Dans cet article, nous allons vous expliquer comment créer data guard un data guard à l'aide du nom de service.
Avant de commencer à expliquer les étapes, les conditions préalables suivantes doivent être remplies :
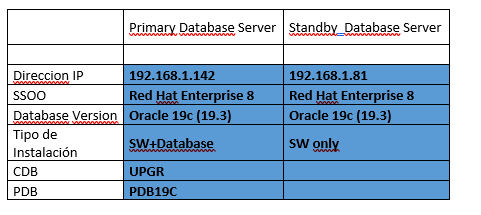
Deux serveurs ont été configurés avec Oracle (19.3). Sur le serveur principal (oracle21), une base de données CDB comprenant une PDB a été créée, tandis que sur le serveur secondaire (oracle21dg), seul Oracle a été installé, sans base de données. Sur les deux serveurs, le stockage configuré est ASM.
BASE DE DONNÉES PRINCIPALE
1. Mettre la base de données en mode « force logging ».
Il est recommandé de forcer la base de données à enregistrer les modifications afin que toutes les modifications apportées à la base de données soient répliquées dans notre base de données de secours, quelle que soit la configuration des objets en « nologging ».
Pour cela, nous exécutons : `
alter database force logging;` ;
oracle> sqlplus / as sysdba
SQL*Plus: version 19.0.0.0.0 – Production, mardi 12 mai 2026 à 19 h 12 min 24 s
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. Tous droits réservés.
Connecté à :
Oracle 19c Enterprise Edition Release 19.0.0.0.0 – Production
Version 19.3.0.0.0
SQL> alter database force logging;
Base de données modifiée.
SQL> exit
Déconnecté de Oracle 19c Enterprise Edition Release 19.0.0.0.0 – Production
Version 19.3.0.0.0
oracle>
2. Création des journaux de reprise de secours.
Nous allons maintenant créer les journaux de redo qui permettent à l'application d'effectuer des opérations de redo en temps réel.
Bonnes pratiques concernant les journaux de réécriture ;
- Les journaux de reprise de secours doivent avoir la même taille que les journaux de reprise.
- Avoir autant de groupes affectés à un fil de configuration RAC
- Qu'il s'agisse de groupes composés d'un seul membre.
- Avoir le même nombre de groupes par thread que les groupes de journaux de redo.
Nous avons vérifié les journaux de redo existants et leur taille (primaires).
select thread#, group#, bytes/1024/1024 MB, status from v$log;
oracle> sqlplus / as sysdba
SQL> select thread#,group#,bytes/1024/1024 MB, status from v$log;
THREAD# GROUP# MB STATUS
————————————————————
1 1 200 INACTIVE
1 2 200 CURRENT
1 3 200 INACTIVE
Dans ce cas, nous avons 3 groupes, pour un seul thread#, et la taille de chacun est de 200 Mo.
Nous exécutons la commande suivante. Il est recommandé de créer un fichier redo log de secours supplémentaire, en plus des fichiers redo logs. Il faut donc 4 fois le nombre de threads de fichiers redo logs de secours de 200 Mo.
alter database add standby logfile thread 1
group 7 (‘+DATA’) size 209715200,
group 8 (+’DATA’) size 209715200,
group 9 (‘+DATA’) taille 209715200,
groupe 10 (‘+DATA’) taille 209715200;
Nous vérifions qu'ils ont bien été créés.
select THREAD#, a.GROUP#, member from v$standby_log a,
v$logfile b where a.GROUP#=b.GROUP# order by 1,2,3; 2
THREAD # GROUP # MEMBER
———— —————- ————————————————————————
1 7 +DATA/UPGR/ONLINELOG/group_7.260.1233147371
1 8 +DATA/UPGR/ONLINELOG/group_8.289.1233150865
1 9 +DATA/UPGR/ONLINELOG/group_9.287.1233147383
1 10 +DATA/UPGR/ONLINELOG/group_10.288.1233147399
3. Activer la gestion des fichiers en veille
Nous nous assurons que, dans la base de données, le paramètre STANDBY_FILE_MANAGEMENT est défini sur AUTO.
SQL> alter system set STANDBY_FILE_MANAGEMENT=AUTO scope=both ;
Système modifié.
SQL> show parameter STANDBY_FILE_MANAGEMENT
NOM TYPE VALEUR
———————————— ———– ——————————
standby_file_management chaîne AUTO
SQL>
3. On copie le fichier contenant les mots de passe
Nous copions le fichier de mots de passe de la base de données principale vers la base de données de secours.
Nous recherchons le fichier contenant les mots de passe sur le serveur principal :
oracle> srvctl config database -d UPGR | grep mot de passe
Fichier de mot de passe: +DATA/UPGR/PASSWORD/orapwUPGR
Nous avons extrait le fichier de mots de passe ASM pouvoir l'envoyer au serveur de secours.
asmcmd cp +FRA/TESTING/PASSWORDFILE/orapwtesting /tmp
Nous envoyons le fichier contenant les mots de passe au serveur de secours.
oracle> scp orapwUPGR oracle:/tmp
oracle Mot de passeoracle:
orapwUPGR 100 % 2048 780,9 Ko/s 00:00
oracle> cp orapwUPGRoracle
4. Nous créons un fichier pfile pour le serveur de secours à partir du fichier pfile du serveur principal, puis nous le copions via SCP sur le serveur de secours.
oracle> scp initUPGR.ora oracle:/tmp
oracle Mot de passeoracle:
initUPGR.ora
5. Nous modifions le fichier PFILE dans la base de données de secours
Nous mettons en place la structure nécessaire :
mkdir -poracle
Dans notre cas, les modifications sont minimes. Nous avons remplacé « UPGR » par « UPGRDG ».
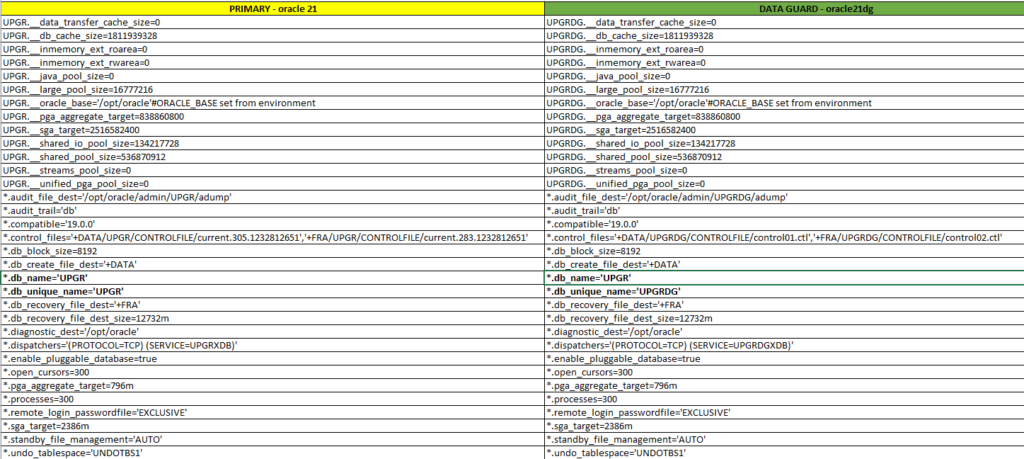
Important : le nom de la base de données (db_name) doit rester le même, mais il faut modifier le nom unique de la base de données (db_unique_name).
oracle> cat UPGRDG.ora
oracle
ORACLEoracle
ORACLEoracle
ORACLE
export ORACLE
export ORACLE
export ORACLE
oracle/.local/bin:/oracle:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:oracle
oracle
export TNS_ADMIN
export ORACLE
Paramètres d'environnement utilisés pour la gestion de la base de données de secours.
Nous avons redémarré la base de données en mode « standby » sans montage, en utilisant le fichier pfile créé précédemment.
Nous arrêtons la base de données, l'enregistrons dans le cluster et la redémarrons en mode nomount.
Avant de continuer, nous allons enregistrer notre nouvelle base de données de secours dans le cluster.
oracle> srvctl add database -d UPGRDG -oraclehomeoracle-diskgroup DATA,FRA -role physical_standby -pwfile +DATA/UPGRDG/PASSWORD/orapwUPGRDG -spfile +DATA/UPGRDG/PARAMETERFILE/spfileUPGRDG
Nous avons démarré la base de données en mode « nomount ».
oracle> srvctl start database -d UPGRDG -o nomount
6. Nous créons les fichiers tnsnames.ora qui pointent vers les deux serveurs
Sur les deux serveurs, nous devons disposer des entrées vers la base de données principale et vers la base de données de secours.
oracle> cat tnsnames.ora
PRIMARY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.142)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = UPGR)
)
)
STANDBY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.81)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = UPGRDG)
)
)
Nous avons vérifié sur les deux serveurs que nous pouvions nous connecter à chacune des bases de données hébergées sur nos serveurs.
oracle> sqlplus sys/***@PRIMARY as sysdba
SQL*Plus
SQL*Plus: version 19.0.0.0.0 – Production, le mercredi 13 mai à 18 h 58 min 30 s 2026
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. Tous droits réservés.
Connecté à :
Oracle 19c Enterprise Edition Release 19.0.0.0.0 – Production
Version 19.3.0.0.0
SQL> exit
Déconnecté de Oracle 19c Enterprise Edition Release 19.0.0.0.0 – Production
Version 19.3.0.0.0
oracle> sqlplus sys/***@STANDBY as sysdba
SQL*Plus: version 19.0.0.0.0 – Production le mercredi 13 mai à 18 h 58 min 41 s 2026
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. Tous droits réservés.
Connecté à :
Oracle 19c Enterprise Edition Version 19.0.0.0.0 – Production
Version 19.3.0.0.0
7. Nous restaurons le fichier de contrôle sur le serveur de secours
La première étape consiste à restaurer le fichier de contrôle en le configurant pour qu'il pointe vers le service de la base de données principale.
Pour cela, j'ai ce script que tu peux appliquer à ta base de données
Nous créons le script 01-restore_controlfile.sh, puis nous l'exécutons.
srvctl stop database -d $ORACLE_UNQNAME -o abort
rman target / << EOF
run{
startup nomount
restore standby controlfile from service «PRIMARY»;
}
exit
EOF
srvctl stop database -d $ORACLE_UNQNAME -o abort
srvctl start database -d $ORACLE_UNQNAME -o mount
oracle> sh -x ./01-restore_controlfile.sh
+ srvctl stop database -d UPGRDG -o abort
PRCC-1016 : UPGRDG a déjà été arrêté
+ rman target /
Recovery Manager : Version 19.0.0.0.0 - Production le vendredi 15 mai à 05:16:12 2026
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle ses filiales. Tous droits réservés.
connecté à la base de données cible (non démarrée)
RMAN> 2> 3> 4>
Oracle démarrée
Zone globale du système totale 2516582152 octets
Taille fixe 9137928 octets
Taille variable 553648128 octets
Tampons de base de données 1946157056 octets
Tampons de redo 7639040 octets
Démarrage de la restauration le 15-MAI-26
en utilisant le fichier de contrôle de la base de données cible au lieu du catalogue de récupération
canal alloué : ORA_DISK_1
canal ORA_DISK_1 : SID=44 type de périphérique=DISK
canal ORA_DISK_1 : démarrage de la restauration du jeu de sauvegardes des fichiers de données
canal ORA_DISK_1 : utilisation du jeu de sauvegardes réseau provenant du service PRIMARY
canal ORA_DISK_1 : restauration du fichier de contrôle
canal ORA_DISK_1 : restauration terminée, durée écoulée : 00:00:06
nom du fichier de sortie=+DATA/UPGRDG/CONTROLFILE/control01.ctl
nom du fichier de sortie=+FRA/UPGRDG/CONTROLFILE/control02.ctl
Restauration terminée le 15 mai 2026
RMAN>
Recovery Manager terminé.
+ srvctl stop database -d UPGRDG -o abort
PRCC-1016 : UPGRDG a déjà été arrêté
+ srvctl start database -d UPGRDG -o mount
8. Nous restaurons la base de données via le nom du service.
Pour cela, nous allons créer un autre script : 02_restore_db.sh. Les bases de données doivent être en mode archivelog.
Important !! Si votre base de données est chiffrée avec TDE, vous devrez copier le fichier TDE de la base de données principale vers la base de données de secours avant de lancer la restauration.
rman target sys/***@STANDBY << EOF
run{
allocate channel c1 type disk;
allocate channel c2 type disk;
allocate channel c3 type disk;
allocate channel c4 type disk;
allocate channel c5 type disk;
restore database from service «PRIMARY» section size 100G;
switch datafile all;
}
exit
EOF
srvctl status database -d $ORACLE_UNQNAME
<pre>oracle@oracle21dg> sh -x ./02_restore_db.sh
+ rman target sys/oracle@STANDBY
Recovery Manager: Release 19.0.0.0.0 - Production on Fri May 15 06:10:06 2026
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
connected to target database: UPGR (DBID=369639787, not open)
RMAN> 2> 3> 4> 5> 6> 7> 8> 9>
using target database control file instead of recovery catalog
allocated channel: c1
channel c1: SID=42 device type=DISK
allocated channel: c2
channel c2: SID=1 device type=DISK
allocated channel: c3
channel c3: SID=45 device type=DISK
allocated channel: c4
channel c4: SID=44 device type=DISK
allocated channel: c5
channel c5: SID=52 device type=DISK
Starting restore at 15-MAY-26
channel c1: starting datafile backup set restore
channel c1: using network backup set from service PRIMARY
channel c1: specifying datafile(s) to restore from backup set
channel c1: restoring datafile 00001 to +DATA/UPGR/DATAFILE/system.271.1233295843
channel c1: restoring section 1 of 1
channel c2: starting datafile backup set restore
channel c2: using network backup set from service PRIMARY
channel c2: specifying datafile(s) to restore from backup set
channel c2: restoring datafile 00003 to +DATA/UPGR/DATAFILE/sysaux.266.1233295845
channel c2: restoring section 1 of 1
channel c3: starting datafile backup set restore
channel c3: using network backup set from service PRIMARY
channel c3: specifying datafile(s) to restore from backup set
channel c3: restoring datafile 00004 to +DATA/UPGR/DATAFILE/undotbs1.260.1233295849
channel c3: restoring section 1 of 1
channel c4: starting datafile backup set restore
channel c4: using network backup set from service PRIMARY
channel c4: specifying datafile(s) to restore from backup set
channel c4: restoring datafile 00005 to +DATA/UPGR/51692FD4BC27283DE065000000000001/DATAFILE/system.259.1233295861
channel c4: restoring section 1 of 1
channel c5: starting datafile backup set restore
channel c5: using network backup set from service PRIMARY
channel c5: specifying datafile(s) to restore from backup set
channel c5: restoring datafile 00006 to +DATA/UPGR/51692FD4BC27283DE065000000000001/DATAFILE/sysaux.273.1233295901
channel c5: restoring section 1 of 1
channel c3: restore complete, elapsed time: 00:01:36
channel c3: starting datafile backup set restore
channel c3: using network backup set from service PRIMARY
channel c3: specifying datafile(s) to restore from backup set
channel c3: restoring datafile 00007 to +DATA/UPGR/DATAFILE/users.272.1233295949
channel c3: restoring section 1 of 1
channel c3: restore complete, elapsed time: 00:00:50
channel c3: starting datafile backup set restore
channel c3: using network backup set from service PRIMARY
channel c3: specifying datafile(s) to restore from backup set
channel c3: restoring datafile 00008 to +DATA/UPGR/51692FD4BC27283DE065000000000001/DATAFILE/undotbs1.265.1233296003
channel c3: restoring section 1 of 1
channel c3: restore complete, elapsed time: 00:01:45
channel c3: starting datafile backup set restore
channel c3: using network backup set from service PRIMARY
channel c3: specifying datafile(s) to restore from backup set
channel c3: restoring datafile 00009 to +DATA/UPGR/5169EC3316F93919E065000000000001/DATAFILE/system.270.1233296115
channel c3: restoring section 1 of 1
channel c4: restore complete, elapsed time: 00:04:30
channel c4: starting datafile backup set restore
channel c4: using network backup set from service PRIMARY
channel c4: specifying datafile(s) to restore from backup set
channel c4: restoring datafile 00010 to +DATA/UPGR/5169EC3316F93919E065000000000001/DATAFILE/sysaux.269.1233296135
channel c4: restoring section 1 of 1
channel c5: restore complete, elapsed time: 00:04:23
channel c5: starting datafile backup set restore
channel c5: using network backup set from service PRIMARY
channel c5: specifying datafile(s) to restore from backup set
channel c5: restoring datafile 00011 to +DATA/UPGR/5169EC3316F93919E065000000000001/DATAFILE/undotbs1.268.1233296153
channel c5: restoring section 1 of 1
channel c2: restore complete, elapsed time: 00:06:55
channel c2: starting datafile backup set restore
channel c2: using network backup set from service PRIMARY
channel c2: specifying datafile(s) to restore from backup set
channel c2: restoring datafile 00012 to +DATA/UPGR/5169EC3316F93919E065000000000001/DATAFILE/users.267.1233296263
channel c2: restoring section 1 of 1
channel c5: restore complete, elapsed time: 00:02:06
channel c2: restore complete, elapsed time: 00:00:44
channel c3: restore complete, elapsed time: 00:03:39
channel c1: restore complete, elapsed time: 00:08:36
channel c4: restore complete, elapsed time: 00:03:48
Finished restore at 15-MAY-26
released channel: c1
released channel: c2
released channel: c3
released channel: c4
released channel: c5
RMAN>
Recovery Manager complete.
+ srvctl status database -d UPGRDG
La base de datos no se está ejecutando.
</pre>
9. Effacer le fichier journal
Tous les fichiers redo logs et les fichiers standby redo logs sont nettoyés afin de les adapter à la nouvelle base de données (standby),
Nous créons un fichier 03-clear_online.sql et l'exécutons dans la base de données standy.
begin
for log_cur in (select group# group_no from v$standby_log)
loop
execute immediate ‘alter database clear logfile group ‘||log_cur.group_no;
end loop;
end;
/
SQL> @03_clear_online.sql
Procédure PL/SQL terminée avec succès.
/
Procédure PL/SQL terminée avec succès.
9. Configuration de Data Broker
Pour centraliser et simplifier un environnement Data Guard, il est fortement recommandé de configurer Oracle Data Guard . Dans le cas contraire, toutes les opérations devront être effectuées manuellement.
Veille
alter system set dg_broker_config_file1=’+DATA/UPGRDG/dr1.dat’ scope=both sid=’*’;
alter system set dg_broker_config_file2=’+FRA/UPGRDG/dr2.dat’ scope=both sid=’*’;
SQL> show parameter broker
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
connection_brokers chaîne ((TYPE=DEDICATED)(BROKERS=1)),
((TYPE=EMON)(BROKERS=1))
dg_broker_config_file1 chaîne oracle
_1/dbs/dr1UPGR.dat
dg_broker_config_file2 chaîne oracle
_1/dbs/dr2UPGR.dat
dg_broker_start booléen FALSE
use_dedicated_broker boolean FALSE
SQL> alter system set dg_broker_config_file1='+DATA/UPGRDG/dr1.dat' scope=both sid='*';
alter system set dg_broker_config_file2='+FRA/UPGRDG/dr2.dat' scope=both sid='*';
Système modifié.
SQL> SQL>
Système modifié.
SQL> show parameter broker
NOM TYPE VALUE
------------------------------------ ----------- ------------------------------
connection_brokers chaîne ((TYPE=DEDICATED)(BROKERS=1)),
((TYPE=EMON)(BROKERS=1))
dg_broker_config_file1 chaîne +DATA/UPGRDG/dr1.dat
dg_broker_config_file2 string +FRA/UPGRDG/dr2.dat
dg_broker_start boolean FALSE
use_dedicated_broker boolean FALSE
SQL>
Primaire
alter system set dg_broker_config_file1=’+DATA/UPGR/dr1.dat’ scope=both sid=’*’;
alter system set dg_broker_config_file2=’+FRA/UPGR/dr2.dat’ scope=both sid=’*’;
SQL> show parameter broker
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
connection_brokers chaîne ((TYPE=DEDICATED)(BROKERS=1)),
((TYPE=EMON)(BROKERS=1))
dg_broker_config_file1 chaîne oracle
_1/dbs/dr1UPGR.dat
dg_broker_config_file2 chaîne oracle
_1/dbs/dr2UPGR.dat
dg_broker_start booléen FALSE
use_dedicated_broker boolean FALSE
SQL> alter system set dg_broker_config_file1='+DATA/UPGRDG/dr1.dat' scope=both sid='*';
alter system set dg_broker_config_file2='+FRA/UPGRDG/dr2.dat' scope=both sid='*';
Système modifié.
SQL> SQL>
Système modifié.
SQL> show parameter broker
NOM TYPE VALUE
------------------------------------ ----------- ------------------------------
connection_brokers chaîne ((TYPE=DEDICATED)(BROKERS=1)),
((TYPE=EMON)(BROKERS=1))
dg_broker_config_file1 chaîne +DATA/UPGRDG/dr1.dat
dg_broker_config_file2 string +FRA/UPGRDG/dr2.dat
dg_broker_start boolean FALSE
use_dedicated_broker boolean FALSE
SQL>
Nous avons activé Oracle Broker sur les deux bases de données.
Veille
SQL> alter system set dg_broker_start=true scope=both sid=’*’ ;
SQL> alter system register;
Primaire
SQL> alter system set dg_broker_start=true scope=both sid=’*’;
Nous enregistrons les bases de données dans Oracle DataGuard Broker de la manière suivante :
Primary : dgmgrl
connect sys/password@PRIMARY as sysdba
CREATE CONFIGURATION dgconfigUPGR AS PRIMARY DATABASE IS UPGR CONNECT IDENTIFIER IS PRIMARY;
ADD DATABASE ‘UPGRDG’ AS CONNECT IDENTIFIER IS ‘STANDBY’;
show configuration;
dgmgrl
DGMGRL pour Linux: version 19.0.0.0.0 – Production le vendredi 15 mai à 15 h 37 min 59 s 2026
Version 19.3.0.0.0
Bienvenue dans DGMGRL, tapez « help » pour obtenir des informations.
DGMGRL> connect sys/***@PRIMARY as sysdba
Connecté à «UPGR»
Connecté en tant que SYSDBA.
DGMGRL> CREATE CONFIGURATION dgconfigUPGR AS PRIMARY DATABASE IS UPGR CONNECT IDENTIFIER IS PRIMARY;
Configuration « dgconfigupgr » créée avec la base de données principale « upgr »
ADD DATABASE ‘UPGRDG’ AS CONNECT IDENTIFIER IS ‘STANDBY’;
Base de données « UPGRDG » ajoutée
DGMGRL> show configuration
Configuration – dgconfigupgr
Mode de protection : MaxPerformance
Membres :
upgr – Base de données principale
UPGRDG – Base de données de secours physique
Basculement rapide : désactivé
État de la configuration :
DISABLED
Avant d'activer cette configuration, il est recommandé de redémarrer la base de données de secours.
srvctl stop database -d UPGRDG
srvctl start database -d UPGRDG -o mount
Il ne reste plus qu'à activer la configuration oracle data guard à l'aide de la commande « enable configuration » ;
DGMGRL> enable configuration ;
Activé.
Nous vérifions que tout est correct ; le statut est « SUCCESS ».
DGMGRL> show configuration
Configuration – dgconfigupgr
Mode de protection : MaxPerformance
Membres :
upgr – Base de données principale
UPGRDG – Base de données de secours physique
Basculement rapide : Désactivé
État de la configuration :
SUCCÈS ( état mis à jour il y a 38 secondes)
Dans cet article, nous avons configuré une base de données à instance unique, mais ces étapes s'appliquent également à un environnement RAC. Il vous suffira d'ajuster les paramètres spécifiques à un environnement RAC dans le fichier init.ora ; pour le reste, les étapes sont similaires.